
The modern digital landscape has reached a point where user data is no longer merely indexed for search but is systematically utilized to train sophisticated artificial intelligence models by default. As technology companies seek to refine their generative algorithms, the baseline settings for many services have shifted to include personal images, audio files, and search history in their developmental datasets. While these integrations often promise improved personalization and efficiency, the lack of transparency regarding when and how this data is utilized has prompted a surge in privacy concerns among consumers worldwide. This development marks a new era in the relationship between service providers and users, where maintaining digital autonomy requires a deep understanding of complex account configurations that were previously considered secondary. Without proactive intervention, private digital assets can inadvertently become permanent components of massive machine learning frameworks. Recognizing these shifts is the first step toward regaining control.
1. Account Configuration: Authentication and Dashboard Controls
Managing the privacy of a digital footprint begins with the fundamental step of properly authenticating into the specific account where these training permissions are active. Since individuals frequently maintain multiple profiles for various professional and personal needs, ensuring that the correct identity is being managed is fundamental to applying any restrictive changes across the entire device ecosystem. This authentication process is not merely a security formality but a prerequisite for accessing the nested settings that govern how media is handled and archived by the underlying systems. By verifying the account identity, a user ensures that any modifications made to data retention policies are synchronized correctly across all connected hardware, from mobile devices to desktop workstations. This initial point of entry serves as the foundation for all subsequent hardening efforts, providing the necessary authorization to modify the internal data processing policies that dictate how private information is leveraged.
Once the session is securely established, the focus must shift to the Activity Controls hub, which serves as the central command center for all data tracking and retention policies. This specialized dashboard provides a comprehensive view of the diverse data streams, such as search history and location patterns, that are collected and utilized by internal algorithms for model refinement. Navigating to this section requires locating the privacy and data management tools within the general account settings, where these granular options are typically situated. The Activity Controls area is critical because it houses the master switches for background processes that influence how personal information is aggregated for machine learning and artificial intelligence training. Successfully reaching this dashboard allows an individual to evaluate which aspects of their digital life are currently being recorded and which categories require immediate restriction to maintain a higher level of privacy in an increasingly automated world.
2. Media Management: Identifying History and Training Toggles
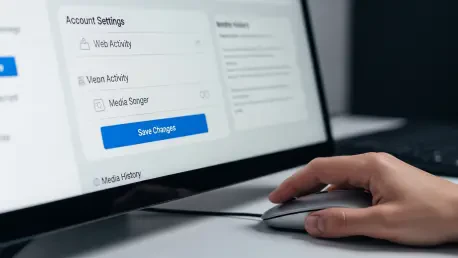
Within the intricate structure of activity management, a new section entitled Search Services History has emerged to categorize interactions involving various forms of media. This area is specifically tailored to manage the lifecycle of images, audio clips, and other file-based data that may be ingested into training pipelines for generative systems. Users should meticulously inspect their Activity Controls page to determine if this update has been applied to their account, as feature rollouts often occur in staggered stages across different regions. Identifying this section is a vital step for those who wish to separate standard text-based logging from more intrusive forms of media harvesting. The presence of this distinct category indicates a change in how different data types are treated, offering a rare opportunity to target specific files for exclusion from developmental datasets. Recognizing this layout is essential for making informed decisions about which historical records should remain active and which should be siloed.
If the Search Services History section is present, the most impactful action is to locate and deactivate the specific toggle dedicated to the saving of media assets. This setting acts as a gatekeeper, determining whether the service is permitted to retain files such as photos and voice recordings for the explicit purpose of developing and enhancing its artificial intelligence infrastructure. Disabling this toggle offers a precise solution that allows users to keep their general search logs for utility while strictly preventing the long-term storage of media for model training. This distinction is paramount because it protects the privacy of visual and auditory materials that might contain sensitive personal details without stripping away the benefits of a personalized search experience. By switching this toggle off, the user provides a direct command to the system to exclude these specific data types from its AI training pools, prioritizing personal privacy over the optimization of massive machine learning models.
3. Comprehensive Measures: Category Disabling and Web Activity
For those who desire an absolute approach to data protection, the option to disable the entire Search Services History section provides a robust alternative to selective toggling. While granular control is useful, the wholesale deactivation of this category ensures that no interactions within these specific services are recorded or leveraged for any purpose, including future AI training. This broad approach prevents the system from generating a detailed profile based on specialized search behaviors, although it may lead to a reduction in the personalization of future search results. Choosing this path demonstrates a prioritization of maximum privacy, as it eliminates the potential for accidental data leakage into developmental sets through overlooked sub-settings. It is a strategic choice that balances the utility of algorithmic personalization against the security of knowing that specialized search activity is no longer being archived for the long term, providing a definitive end to data collection.
In instances where the media-specific menus are not yet visible, the most effective safeguard is the complete cessation of Web and App Activity tracking. By disabling this overarching setting, a user ensures that even as new AI training defaults are introduced, the fundamental permissions for data harvesting will remain deactivated. This measure halts the tracking of interactions across the entire ecosystem of services, providing a layer of security that prevents information from being gathered for training purposes. This approach is particularly useful during transition periods when new privacy controls are being deployed at different rates for different users. Shutting down this main activity stream sends a clear signal to the platform that no behavioral data should be utilized for the refinement of internal algorithms. It serves as a proactive defense mechanism, protecting the integrity of a user’s data regardless of whether the specific media-related menus have been added to their individual account dashboard yet.
4. Final Security Refinements: Individual Toggles and Ongoing Oversight
Further refinement of privacy settings can be achieved by specifically unchecking the individual tracking boxes for voice and audio activity as well as visual search history. These granular controls address the specific types of data most valuable to generative AI models, such as speech patterns and image recognition metadata. Even if the broader activity tracking is not entirely disabled, targeting these categories allows for a more focused approach to data protection. By deselecting these options, users prevent the storage of vocal and visual interactions, which are primary targets for training voice synthesis and image generation systems. This level of detail in account management ensures that the most personal aspects of a digital life remain excluded from the massive datasets that fuel technological growth. Utilizing these checkboxes provides an additional layer of security, acting as a secondary barrier against the automated collection of media for algorithmic training.
Maintaining a high level of digital privacy is not a one-time event but a continuous process that requires a dedicated schedule for auditing account configurations and activity settings. As technology providers frequently update their data policies and management interfaces, a setting that is disabled today may be superseded by a new category or a different default in the coming months. Establishing a regular reminder to revisit the Activity Controls dashboard ensures that any newly implemented AI training protocols are identified and managed before significant data accumulation occurs. This proactive stance is the only way to guarantee that personal media remains excluded from training sets as the service infrastructure continues to evolve. Verification also involves checking that previous selections remain intact and that no system updates have reset privacy preferences to a more permissive state. By treating account management as a routine task, users can effectively stay ahead of the rapid changes in how their data is leveraged.
The collective shift toward stricter data governance was driven by a significant increase in user awareness regarding how personal assets were being utilized for algorithmic development. Individuals who successfully modified their account permissions established a new standard for digital privacy that prioritized personal sovereignty over uninhibited machine learning growth. This movement forced technology providers to offer more transparent configurations and clearer disclosures about the ingestion of media files into training pipelines. As these adjustments became common practice, the boundary between service utility and personal data protection was more clearly defined, reducing the risks associated with involuntary data scraping. The implementation of these restrictive measures proved that users could effectively influence the lifecycle of their digital content through informed action and persistent auditing of their accounts. Ultimately, the successful management of these defaults ensured that the digital ecosystem remained respectful of individual rights and privacy.







